Race Condition Programming: Meaning, Examples, Causes, and Prevention
A clear guide to race condition programming — what a race condition is, how it happens, race condition vs data race, real-world examples, why they are dangerous, and how to detect and prevent them.

On this page⌄
Most software does many things at once. A single app might load data, take user input, write to a file, and talk to a server inside the same sliver of time. That overlap is what makes modern programs fast, and it is also where one of the most stubborn bugs lives: the race condition. It does not crash on command. It hides during testing, slips past review, then surfaces in production under load you cannot reproduce on your laptop. The good news is that races are understandable and preventable once you know how they form.
What is a race condition in programming?

A race condition happens when two or more threads or processes touch a shared resource at the same time and the result depends on which one gets there first. Run the program twice and the same input can give you two different answers. That unpredictability is called non-deterministic behavior, and it is the whole problem.
Picture two people editing the same document with no coordination. Both open it, both make edits, both hit save. Whoever saves last wins, and the other person's changes vanish. The final file depends on timing, not on what either person intended.
In code, the "document" is any shared resource: a variable in memory, a file on disk, a database row, a hardware register. The "people" are threads or processes running at the same time.
The classic example is a bank balance:
# Thread 1 and Thread 2 run this at the same time
balance = get_balance() # both read 100
balance = balance + 50 # both compute 150
save_balance(balance) # both write 150
Two deposits of $50 against a starting balance of $100 should leave $200. But if both threads read 100 before either writes, the account lands at 150 and one deposit silently disappears. Nothing errors out. The code looks correct. The money is just gone.
That silent failure is what makes race conditions dangerous: no error, no stack trace, just wrong data that nobody asked for.
How race conditions happen
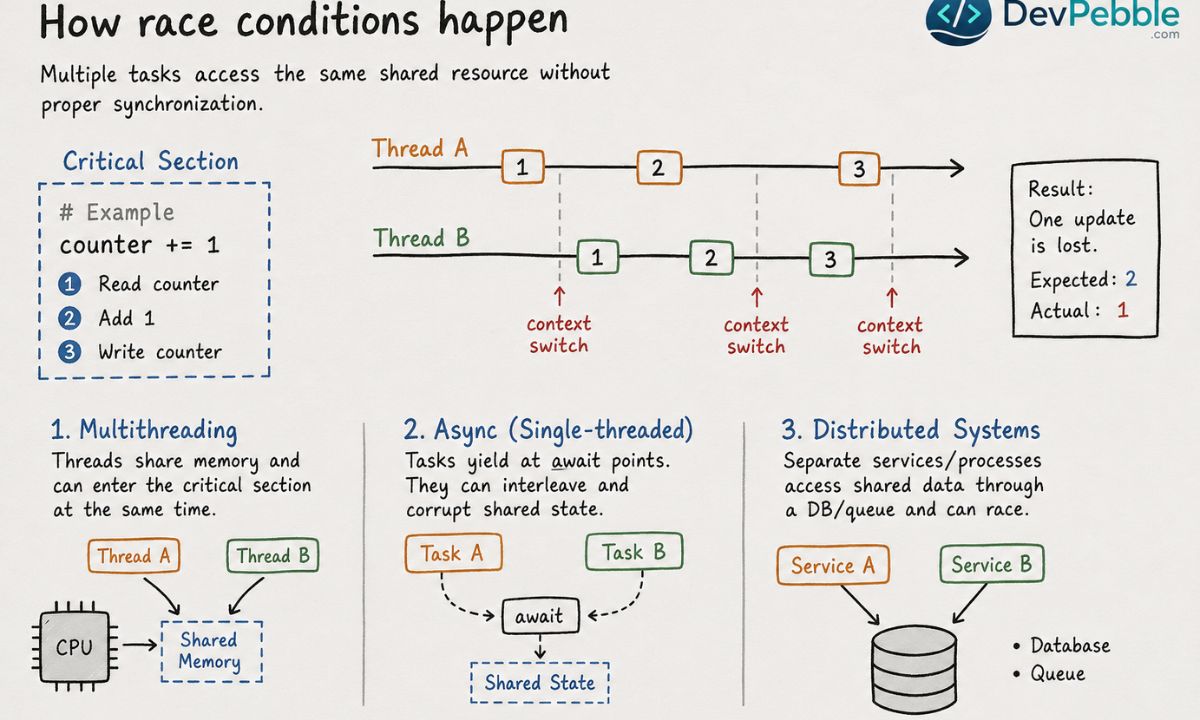
Race conditions are a side effect of concurrency, the ability to run multiple tasks over overlapping periods. In multithreaded code, one process spawns several threads that share the same memory. In parallel programs, work runs at the same instant across multiple CPU cores. Both setups let threads race for the same data.
The stretch of code where a shared resource is read or written is the critical section. If two threads enter a critical section at once with no synchronization, you have a race.
Why the timing is so slippery comes down to how the operating system runs threads. It uses context switching to juggle them, pausing one and resuming another constantly, and a switch can land between any two machine instructions, including in the middle of something that looks atomic in your source. A line as innocent as counter += 1 is three steps underneath: read the value, add one, write it back. A context switch between any two of those steps loses an update. That window can be microseconds wide, which is why a race stays invisible on a quiet dev machine and then fires reliably under production load.
The same trap exists outside classic threading. In asynchronous code, such as Node.js or Python's asyncio, only one task runs at a time, but tasks hand off control at each await point. If two async tasks read and modify the same object across those handoffs, they can interleave and corrupt the result with no real parallelism involved. In distributed systems, services on separate machines share state through a database or a queue and can race exactly like two threads in one process, and there the fix is a distributed lock, often built on Redis or a database transaction.
Race condition vs data race
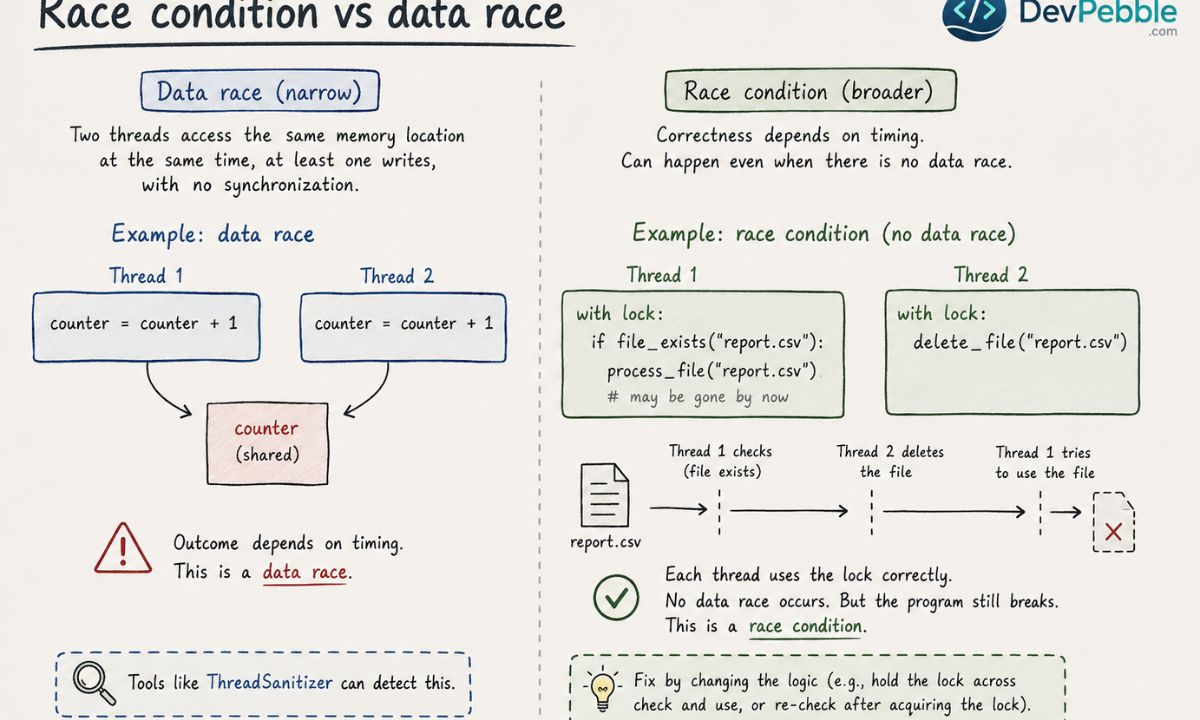
People use "race condition" and "data race" as if they mean the same thing. They do not, and the difference decides which tool will actually help you.
A data race is the narrow, low-level version: two threads touch the same memory location at the same time, at least one is writing, and nothing synchronizes the order. It is precisely defined in most language specifications, which is why tools like ThreadSanitizer can detect it mechanically.
A race condition is the broader idea. It is any situation where correctness depends on timing, and it can exist with no data race at all.
Here is a data race, with no protection on a shared counter:
# Thread 1 # Thread 2
counter = counter + 1 counter = counter + 1
And here is a race condition that has no data race, because the locks are correct but the logic still assumes nothing changes between two operations:
# Thread 1
with lock:
if file_exists("report.csv"):
process_file("report.csv") # may be gone by now
# Thread 2
with lock:
delete_file("report.csv")
Each thread locks properly, so memory access is safe. But if Thread 2 deletes the file between Thread 1's check and its use, Thread 1 still breaks. The bug lives in the timing between two individually safe operations.
So every data race is a memory-access problem, while a race condition is a logic problem that can survive perfect locking. Knowing which one you face tells you whether a sanitizer will catch it or whether you need to rethink the logic.
Common examples of race conditions in real code
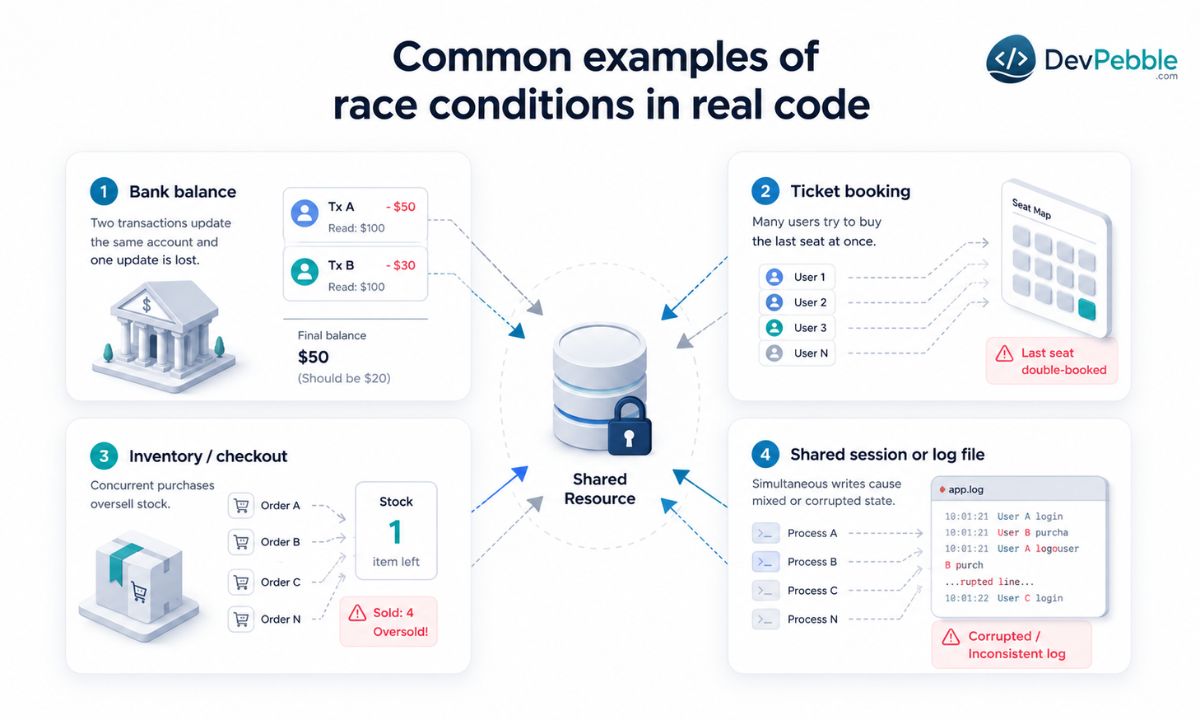
These are not textbook curiosities. They sit inside software people use every day. The bank balance above is the canonical case: two transactions read the same starting figure and one write overwrites the other. Online ticket and seat booking is the same shape with higher stakes, where five hundred requests all read "1 available" and pass the check before any booking finishes, so the seat sells many times over. E-commerce inventory behaves identically and oversells when concurrent checkouts read the count at once. The smaller cases bite too: a visit counter updated from many threads drops counts when an increment is not atomic, two processes appending to one log file produce interleaved or corrupted lines, and a web server holding user sessions in shared memory can scramble session state when two requests for the same user arrive together and neither one locks.
Why race conditions are dangerous

The damage falls into a few buckets, and what ties them together is how hard each one is to trace back to its cause.
Data corruption is the most direct. When two threads write conflicting values to the same place, the stored result matches no valid state the program ever intended. Closely related are incorrect results and duplicate actions: a payment charged twice, or an order placed twice, where each thread reports success because neither knew the other existed.
Security is the less obvious risk. A whole class of attack, time-of-check to time-of-use (TOCTOU), exploits the gap between when a program checks a condition, such as whether a user may open a file, and when it acts on that check. An attacker who can change shared state inside that gap can slip past a permission check and reach something they should not.
Crashes come from the same root. One thread frees or modifies a resource another thread is still using, and you get a null dereference or an invalid memory access that looks like a logic error in code that is individually fine.
The worst part operationally is reproducibility. Because the bug depends on exact scheduling, which shifts with CPU load and hardware, it can appear daily in production and never once in development. Add logging to investigate and the extra I/O changes the timing, so the bug vanishes the moment you look at it. That is a heisenbug, and it is why teams can burn weeks on a single race.
How to detect race conditions

Finding a race needs a different approach than chasing an ordinary logic error, because you cannot just step through and watch it fail.
Thread sanitizers are the strongest automated option. ThreadSanitizer (TSan), available for C, C++, Go, and others, instruments your code at build time and watches memory access at runtime, catching data races that ordinary test runs would never trigger. On the C and C++ side, Valgrind's Helgrind does similar work, and Java developers have IntelliJ IDEA's concurrency inspections plus thread-dump analysis.
Sanitizers catch the mechanical errors. The timing-sensitive ones often need stress testing: run the suspect operation thousands of times in a tight loop, far more than production would, and you raise the odds of hitting the narrow window at least once. To make a test deterministic, start every thread at the same instant with a barrier or latch so they collide in the critical section on purpose.
Logging helps reconstruct what happened, with one catch: it changes timing. A race that reproduces without logging can disappear once you add it, because the extra I/O slows the thread that was winning. Static analyzers such as Coverity and SonarQube flag unsafe patterns like unprotected shared access or inconsistent locking before the code runs. And plain code review aimed at shared mutable state is one of the cheapest detectors there is: train reviewers to ask, at every shared variable, whether two threads could reach it at once and whether every access is protected.
How to prevent race conditions

Prevention is far cheaper than debugging, and most of it comes down to controlling access to shared state.
The most common tool is the mutex, short for mutual exclusion. Think of it as the one key to a locked room: only the thread holding the key can enter the critical section, and everyone else waits.
import threading
lock = threading.Lock()
def update_balance(amount):
with lock:
balance = get_balance()
save_balance(balance + amount)
Inside the with lock block, only one thread runs the update at a time. The rest queue up, so the threads take turns instead of racing. A read-write lock relaxes this when reads vastly outnumber writes, letting many readers in at once but giving writers exclusive access, which suits a config store or a cache.
Locks are not free, though. The worst failure is deadlock: Thread A holds lock 1 and waits for lock 2 while Thread B holds lock 2 and waits for lock 1, and both freeze forever. Lock contention is the quieter cost. When many threads fight over one lock they spend more time waiting than working, and an overly broad lock can throttle throughput as badly as the race it replaced. The rule that prevents both is to keep critical sections small. Protect only the lines that actually touch shared data, never the whole function.
A semaphore is a mutex with a counter. Instead of one thread at a time, it admits up to N, which is handy for capping concurrency, say at most ten open database connections while the rest wait.
semaphore = threading.Semaphore(10)
def query_database():
with semaphore:
run_query()
For simple counters and flags, atomic operations beat locks. An atomic operation is a single hardware instruction that cannot be interrupted partway, so the read-modify-write that normally takes three steps becomes one. Java's java.util.concurrent.atomic, C++'s std::atomic, and Go's sync/atomic all provide atomic integers and booleans that are safe across threads with no lock overhead and no deadlock risk.
Some design choices remove the problem instead of guarding it. Immutable data cannot be corrupted, because a thread that cannot modify a shared object cannot race on it, so create data once and read it many times where you can. Thread-safe structures like Java's ConcurrentHashMap, Python's queue.Queue, and Go's channels handle their own synchronization, so reaching for them instead of a raw dict or list erases a whole category of risk. Message queues go further and drop shared memory altogether: threads post to a queue and one consumer processes them in order, the model behind actor systems. At the data layer, a database transaction with serializable isolation behaves as if it were the only one running, letting the engine handle scheduling.
Beyond the tools, a few habits keep races rare. Reduce shared mutable state first, since every value multiple threads can write is a potential race, so favor local variables, return values, and immutable objects over shared globals. Design for thread safety from the start, because bolting synchronization onto code that never expected it is slow and error-prone. Lean on proven libraries such as Go's sync package, java.util.concurrent, or Rust's ownership model rather than writing your own lock-free structures. And put thread sanitizers in CI, where catching a race costs a fraction of a production incident.
Conclusion
Race conditions are among the most consequential bugs in software, less because they are dramatic and more because they are deceptive. They corrupt data quietly, dodge tests, and surface only under the conditions that make them hardest to reproduce. A balance that is occasionally wrong, a seat sold twice, a counter that drifts: none of it looks like a threading bug until you know the shape.
The fix is mostly discipline. Know your concurrency model, whether that is threads, async tasks, or distributed services. Find every place mutable state is shared and treat each as a critical section. Then use the lightest tool that fits: an atomic for a counter, a mutex for a block of logic, a queue for service-to-service work. Design for it up front instead of patching it in after an incident. With multi-core hardware everywhere and Python itself now moving past the GIL, getting concurrency right is no longer a specialty. It is part of writing software that holds up under load.


